Covid-19 Prognosis Predictor
In this data mining project, the objective was to explore several widely used machine learning models, optimize various hyperparameters, and utilize the best-tuned models to predict COVID-19 case outcomes.
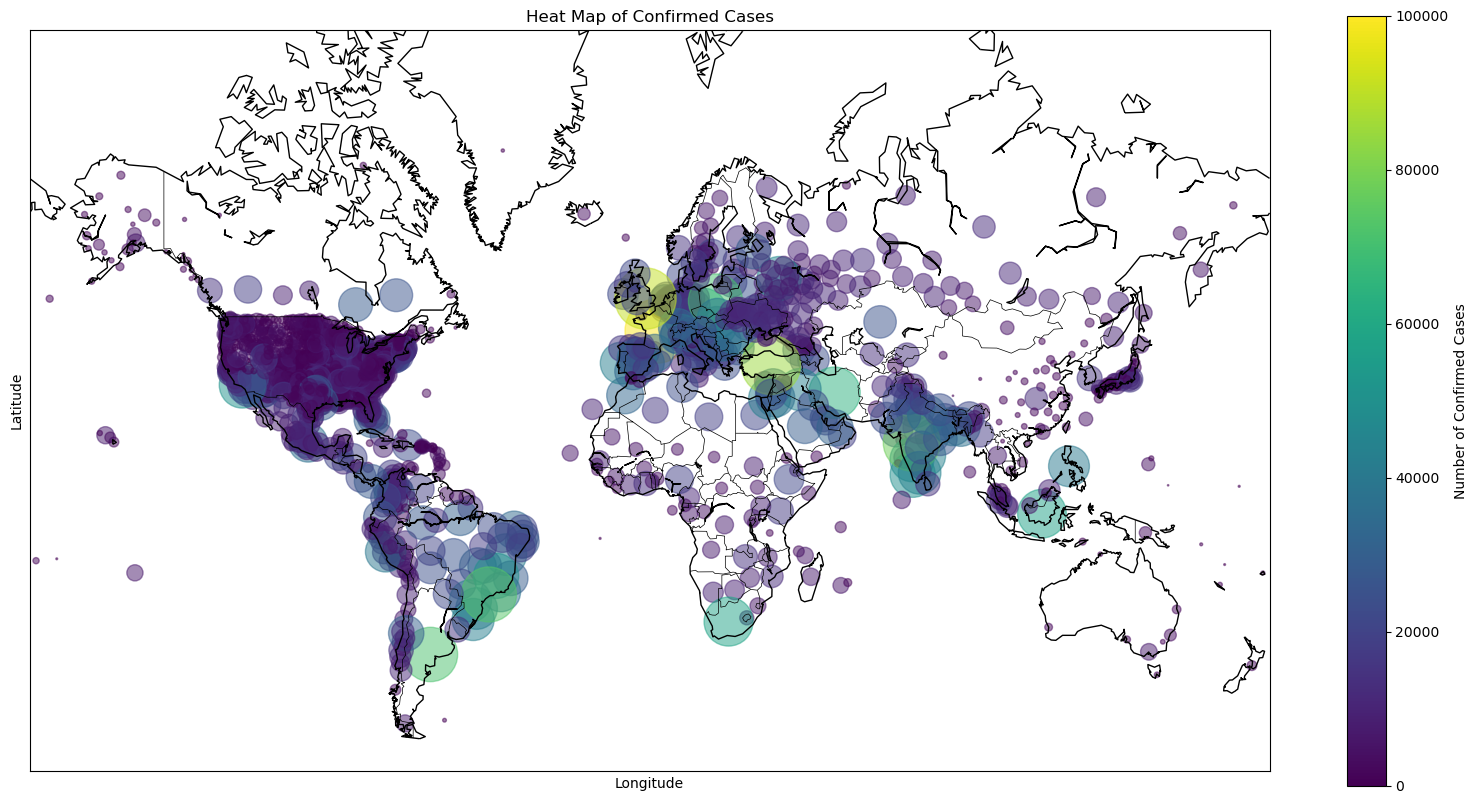
In this data mining project, the objective was to explore several widely used machine learning models, optimize various hyperparameters, and utilize the best-tuned models to predict COVID-19 case outcomes.
Throughout the project, meticulous curation and preprocessing of the data were undertaken, ensuring that the models did not learn from noisy or incomplete information. Relevant features were carefully selected for both training and testing, maintaining consistency to enable accurate model comparisons. Categorical features were mapped, and class distributions were balanced to optimize the datasets for model training, thereby enhancing predictive performance. Building upon this groundwork, various classification models were constructed including KNN, Random Forests, and Naive Bayes Classifier . These models were fine-tuned, utilizing advanced techniques such as hyperparameter tuning and model evaluation to achieve optimal results. Efforts were made to rigorously check for overfitting and conduct comparative analyses to identify the most effective model for the goal. Ultimately, the best-tuned model was utilized to predict outcomes on the test dataset, meeting performance criteria and showcasing the success of the approach in developing a robust and accurate classification solution.